
Technologies
Status
We started this whole journey with n8n. You know the one, that automation tool that promises to be the duct tape for the internet. And look, it was great at first. We felt so clever connecting all our social media accounts into a single workflow.
It looked cool from a distance, but the moment you put any real pressure on it, the whole thing started to wobble.
The Three Horsemen of n8ncalypse
It all really boiled down to three things.
First, it had the memory of a goldfish. I'm not kidding. Zero persistent memory*. Every single time our automation ran, it was a blank slate. It had no clue that it had just posted that YouTube video four hours ago.
*n8n just released workflow persistent data tables. https://docs.n8n.io/data/data-tables/
We ended up with a mess of duplicate draft posts flooding our dashboards. I could’ve added a excel spreadsheet to keep a log, but come on, that’s sticky tape.
Second, "On-Demand" blog posts weren’t a thing. So, a killer new video just dropped. It’s timely. It’s perfect. We need to post it now. My options were... not great.
A) I could just wait for the next scheduled run. Which could be up to 4 hours away. (In internet time, that's an eternity.)
B) I could dive into the n8n interface, manually stop the entire workflow, trigger a single run while holding my breath and praying I didn't break the schedule, and then try to remember to turn it all back on again.
C) Cry.
Third, it had the personality of a brick. This was maybe the most soul-crushing part. Every single piece of content got shoved through the exact same, generic AI prompt.
A super deep, technical video? Same prompt.
A fun, casual event announcement? Same prompt.
An update to our company rules? You already know... same prompt.
The content it spat out was just... bland AI slop that had no nuance, no excitement, no soul. It was obvious an AI wrote it.
Enter the Pipeline Architecture: Now You're Thinking With Portals Pipelines
Instead of trying to fix and patch one monolithic workflow, I built a modular “pipeline system” where content flows through specialized pipes.
Remember GLaDOS Portal? "Now you're thinking with portals!" Well, now we're thinking with pipelines.
```python
# pipelines/base.py - The foundation of our pipeline thinking
@dataclass
class ContentItem:
"""Represents a single unit of work that flows through the pipeline."""
source: str # "youtube", "eventbrite", "ssw_rules"
content_type: str # "video", "event", "rule"
identifier: str # Unique ID for deduplication
payload: Dict[str, Any] # Raw content data
artifacts: Dict[str, Any] # Processed results
status: str = "pending" # Track progress through pipeline
errors: List[str] = field(default_factory=list)
```Each piece of content becomes a ContentItem that flows through specialized pipeline nodes.
Want to add a new content source? Add a new connector.
Need to change how videos are processed? Modify just the video nodes.
For the goldfish memory, solved with Firestore.
It's a database, but for our pipeline. Now, before the pipeline does a single thing, it asks: "Hey Firestore, have you ever seen this video ID before?" If the answer is yes, it just stops. That's it. No more duplicates. The amount of relief that gave me is hard to overstate.
# services/firestore_service.py - Our persistent memory
async def is_video_processed(self, video_id: str) -> bool:
"""Check if a video has already been processed"""
doc_ref = self.client.collection('processed_videos').document(video_id)
doc = doc_ref.get()
return doc.exists
async def mark_video_processed(self, video_id: str, metadata: Dict,
social_content: Dict, okoya_response: Dict) -> bool:
"""Mark a video as processed and store associated data"""
doc_data = {
'video_id': video_id,
'processed_at': datetime.now(),
'video_metadata': metadata,
'generated_content': social_content,
'okoya_response': okoya_response,
'success': okoya_response.get('success', False)
}
doc_ref.set(doc_data)
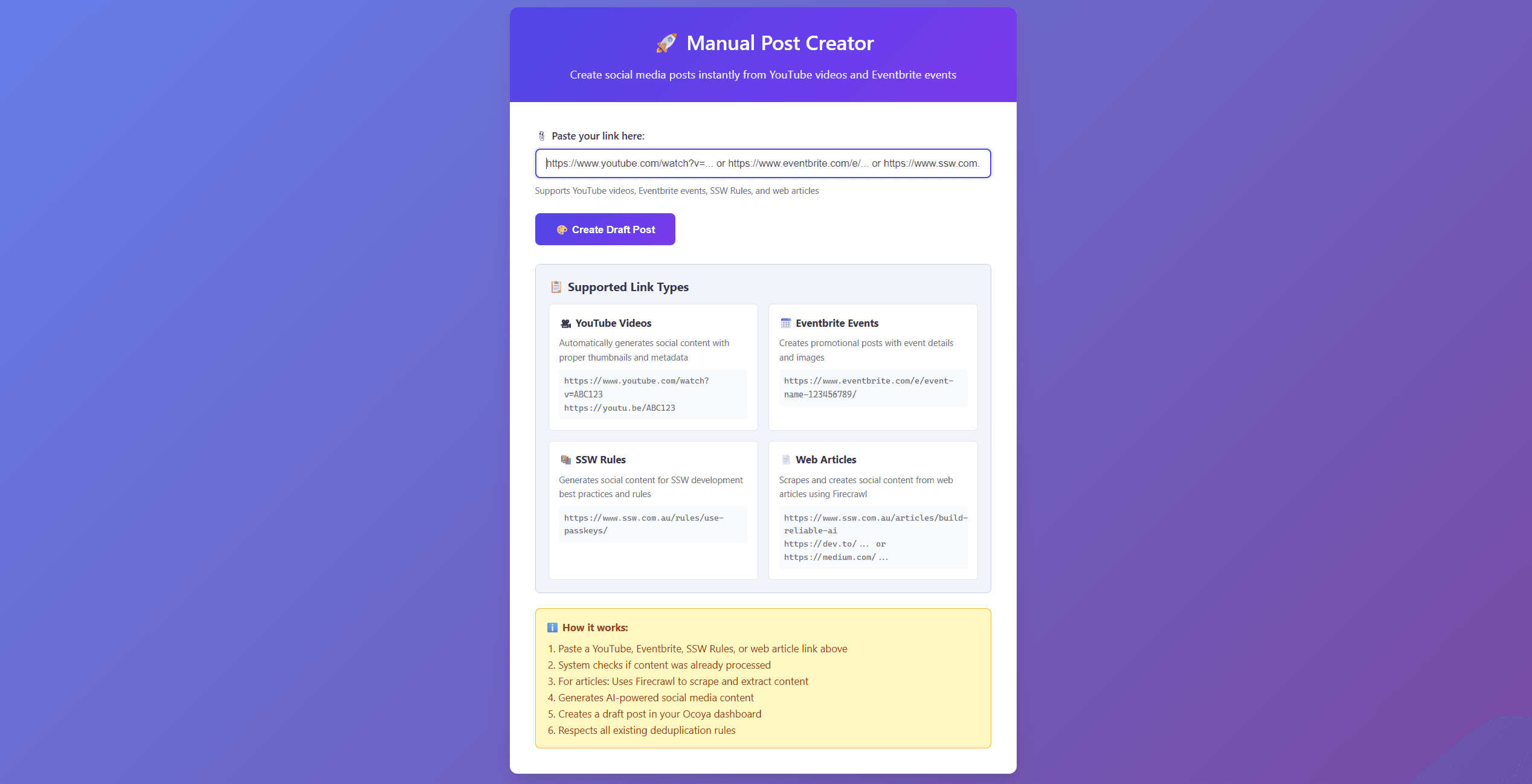
For the agonizing waiting game, I built a frontend to trigger manual mode.
It’s a simple web page with a box to paste a link in. When I have something urgent, I just paste the URL in there and hit "Go." It triggers the exact same pipeline, but on my command.
What about that brick-like personality?
We hired a team of specialist writers. Well, not people. Specialist AI writers.
Now, we have a YouTubeContentWriter that gets the video transcript and can pull out insightful quotes.
We have an EventContentWriter that knows to focus on the date, time, and creating a sense of urgency.
The content finally sounds like it was written by someone who actually knows what they're talking about. It has nuance. It has a voice.
So, here’s what happens now when we publish new content.
Connectorsfetch new videos, articles, events from YouTube, Eventbrite, RSS and so on.Raw data enters the pipeline. The first stop gets its vitals: title, thumbnail, content, metadata, all that good stuff.
If it’s a video, it zips over to the transcript station, which pulls the full text. This is the secret sauce for making the content really smart (and gemini-2.5-flash with that massive 1M context window)
Then, the magic happens. All that info is handed to a dedicated
“ContentWriter”. It uses specialized prompts to craft posts that are actually about the source's content.Those shiny new posts are sent off to our scheduling tool (Ocoya).
And finally, the last stop. The source ID is stamped into our Firestore memory bank with a note: "Done." Never to be posted again.
But Is This... You know... Overkill?
I have to be honest. I got carried away.
I went from a popsicle stick spaceship to Elon’s Starship. This new system is way more complex. It’s running on real Google Cloud infrastructure, it has proper error handling, logging... the works.
For most people? Yeah, it's probably overkill. But that kind of misses the point.
I worked on this task for about what, 4 or 5 days? It was just me, Cursor, and a whole lot of curiosity that got me through the line. At the end of the day, it's all about learning and testing new grounds of AI-assisted coding.
And this system is impressive. It handles multiple content sources, generates specialized content, manages complex posting schedules, and even creates different outputs based on the social media platform (so you don't see the exact same text for Instagram, X, and LinkedIn). And, of course, it maintains that persistent state so it knows what it's done.
Where This is Really Going: More People Pushing Code
This pipeline is cool, yes. But if we zoom out for a second, the tech itself isn't the most interesting part of this story.
The most exciting part is how it was built.
Think about it. A few years ago, a system like this, with multiple cloud services, a database, and different AI models, would have been a multi-week project for a team of developers.
It would've required sprints, backlogs, planning meetings... the whole lot.
I built this in a couple of days with an AI coding assistant basically welded to my fingertips. Shoutout to Cursor, gpt-5-codex and claude-4-sonnet
This is the real sea change.
The barrier to entry for creating serious, powerful, custom tools is crumbling. You, the marketer, the analyst, the operations person, the one who is closest to the problem, no longer have to settle for off-the-shelf tools that almost do what you want.
With this new generation of AI-assisted coding tools, you can build the exact solution you've always had in your head. Today.