
AI quality is nearing expert-level, but the cost of human review eats up the savings. The practical efficiency gains just aren't there... yet
You've seen the headlines. "AI is coming for our jobs!" one day, and "AI can't even create an excel sheet!" the next.
It’s confusing, right? How do we know if these incredibly smart... but sometimes incredibly dumb... AIs are actually ready for the real world?
Passing a tidy benchmark with multiple-choice answers is one thing. Cool, for sure. But can an AI draft a legal brief that won't get you laughed out of court? Can it create a marketing deck that actually sells something?
Basically, can it handle real work? Messy briefs, half-baked inputs, style choices, and ten open tabs.
This is where a new benchmark called GDPval (from OpenAI) comes in, and honestly, it’s a bigger deal than it sounds. It’s designed to test AI on the kind of messy, real-world work that people get paid to do every single day.
For ages, the only way to see a new technology's impact was by looking at things like GDP years later. GDPVal aims to give us a much clearer picture of what's actually happening before it happens.
Think about your own job for a second (sorry).
Is it a series of neat, tidy problems with one right answer? Hopefully Probably not. It's complicated. It's subjective.
You have to deal with spreadsheets, presentations, weirdly formatted documents, and that one coworker who communicates in mystic ways 💫
That's the whole idea behind GDPval. It’s built from the ground up to mirror a real job.
Based on Real Work: The tasks are based on actual work products from industry pros. Legal briefs, engineering blueprints, and nursing care plans. This tests skills that directly matter on the job.
Covers the Whole Economy (Almost): The test covers 44 different jobs across the 9 biggest sectors of the U.S. economy.
It Includes Messy Files: The AI has to work with the same stuff you do, like spreadsheets, presentations, design files, and photos.
Style Matters: In the professional world, how something looks can be as important as what it says. GDPval gets that. Grading includes subjective things like style, formatting, and aesthetics.
NOT Quick Problems: These are complex tasks that would take a human expert about 7 hours on average to complete. They reflect the deep, multi-day projects that define professional work.
Basically, GDPval is a direct, meaningful stress test of an AI's professional chops.
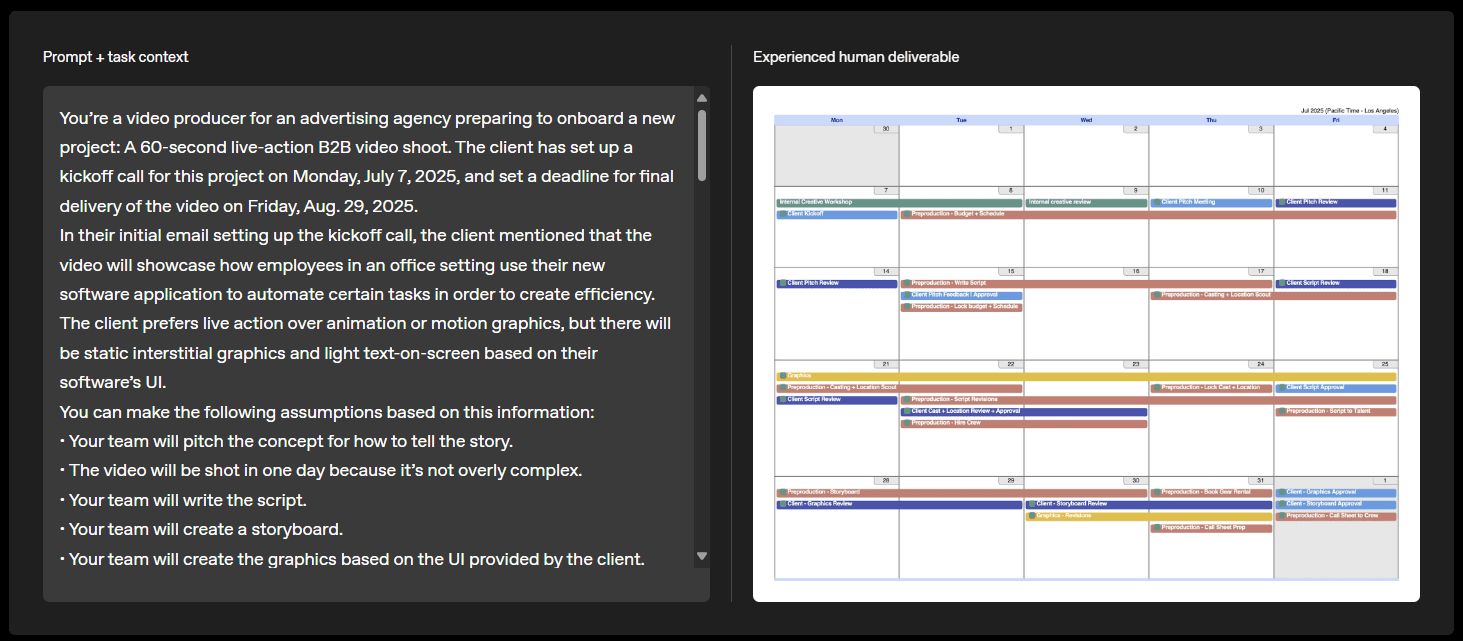
So, how did the researchers actually pull this off? They couldn't just make things up. They needed tasks that were both real and economically important.
First, they selected the nine industrial sectors that are the biggest contributors to the U.S. GDP. We're talking about the big ones: Healthcare, Finance, Manufacturing, you name it. Within those sectors, they picked out 44 high-earning, "digital-first" jobs. To do this, they used the O*NET database from the U.S. Department of Labor, making sure the selected jobs were all about knowledge work.
This is the cool part. Then, they went out and hired seasoned professionals, people with an average of 14 years of experience in their fields. People from places like Google, Disney, JPMorgan Chase, HBO, and even the U.S. Department of Defense. Hardcore real-world experience.
Each expert created assignments based on their actual, day-to-day work. And to make sure everything was top-notch, each task was reviewed by other humans an average of five times before it made the final cut.
They used a method I love: blinded expert pairwise comparisons. It's basically a blind "taste test" for professional work.
An expert in the field (like a lawyer for a legal task) gets the original request. Then, they’re shown two final versions side-by-side, with no labels (taste test). One was made by a human expert, the other by an AI. The expert grader then decides which one is better, or if they're equally good.
And this is intense.
It takes an expert over an hour just to grade a single comparison.
They also tried an automated AI grader. It’s faster and cheaper (obviously), and while it’s not as reliable as a human, it’s still a work in progress, but its agreement with human experts is getting surprisingly close (66% agreement, versus 71% agreement between two different human experts).
Short version: better than last year, not better than your best colleague (yet), and with distinct personalities. Yes, personalities.
AI is Getting Better, Steadily: The performance of the best models on these real-world tasks is improving in a "roughly linear" way over time. This suggests consistent, predictable progress.
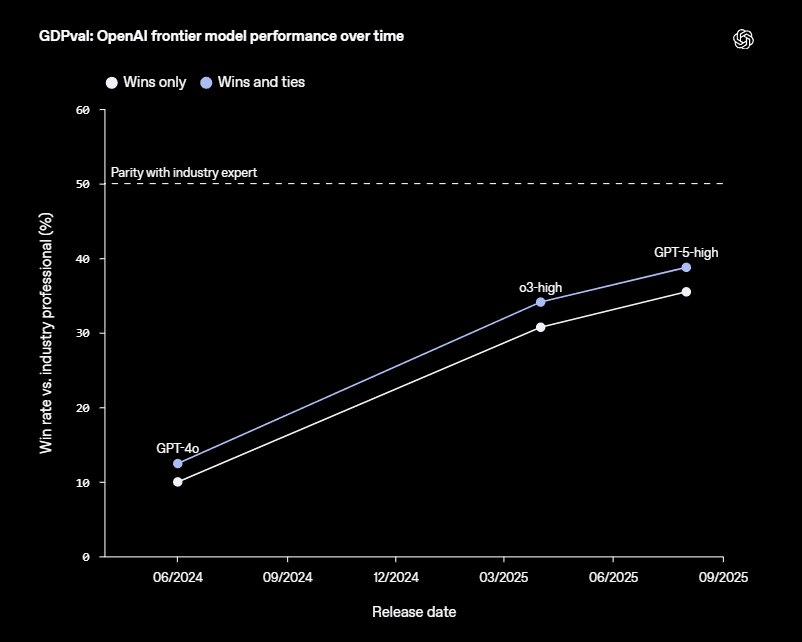
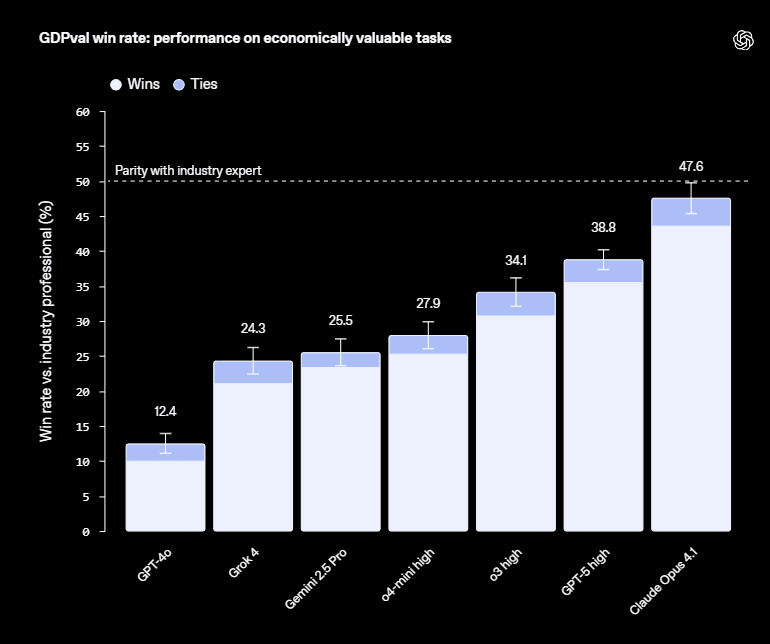
Gap is Closing: The top AIs are "approaching industry experts in deliverable quality." In the tests, the work from the best-performing model was preferred or considered equal to the human expert's work in nearly half the tasks (47.6% to be exact). Frontier AI is already producing work of a professional standard almost half the time.
Different AIs, Different Talents: Just like people, different models have different strengths. Claude Opus 4.1, was especially good at aesthetics, things like formatting and making slides look nice. GPT-5, was stronger on accuracy, carefully following instructions and getting calculations right.
The winning setup today is human + model, with the human deciding where to trust and where to fix. Draft with one, cross-check with the other. Let the AI do the grind; you keep the judgment.
GDP (the macro number) tells us what already happened. Helpful, but late. GDPval shows what might happen to the work before it hits the economy. It moves us away from abstract puzzles and forces us to look at how AI performs on the messy, complex, and often subjective tasks that define real jobs
The team has even open-sourced a part of the test and the experimental auto-grader, so other researchers can build on this work. Love that.
Benchmarks won’t tell you everything. (No benchmark captures Bob’s cryptic comments in Column AA or the “Can we make it pop?” feedback loop.) But GDPval gets a lot closer to reality than most. It respects the truth that work is subjective, long, and made of files. It grades like a client would. It surfaces model strengths you can actually plan around.
Would I run my team purely on these scores? No.
Would I use them to pick which model drafts the first version, which one checks the math, and where I still want a human’s eye? Absolutely.
Frontier models still exhibit failures, some of which are severe. Even when a model fails to outperform a human expert, the most common failure category for GPT-5 was “acceptable but subpar”, meaning the output could be used but was weaker than the human's.
However, approximately a third of failure ratings for GPT-5 were categorized as "bad or catastrophic" (with roughly 3% marked as catastrophic, such as literally recommending fraud or giving a wrong diagnosis).
The analysis noted that it does not capture the cost of catastrophic mistakes, which can be disproportionately expensive in some domains.
Here's the catch. On one hand, the work these AIs produce is getting shockingly good, often standing shoulder-to-shoulder with what a human expert can do. BUT and this is the big, unavoidable "but", you still have to pay an actual expert to check its homework. You just can't skip this step.
And that's the part where the whole "efficiency" promise starts to fall short. The time and money you have to pour into that mandatory expert review basically eats up all the practical savings you were hoping for.
So, while the quality is getting there, the actual time and cost benefits... well, they pretty much vanish into thin air once a human has to get involved.
Scope: 44 occupations across the 9 biggest U.S. sectors
Task realism: Multi-modal, multi-file, average ~7 hours of human effort
Grading: Blinded expert comparisons; experimental auto-grader at 66% agreement (vs 71% human-human)
Performance: Top model (“Claude Opus 4.1”) preferred/equal to human 47.6% of the time; “GPT-5” stronger on accuracy
Open resources: 220-task gold subset + experimental grader available for research.